DevOps
When trying to grasp a new concept or technology I find it helpful to spend some extra time learning about the subject's origins. It gives context and perspective which are crucial for grasping something complex. So before diving into the network automation topic I'd like to drop a few lines about where it all came from.
Of course, in some way network automation has been around for quite a long time. You can remember such examples as using Expect to connect to network devices and issue commands or writing EEM scripts on Cisco routers, or maybe running scripts which retrieve useful information from network devices via SNMP. So what has changed since then? Why network automation is such a hot topic right now? My answer is — the rise of DevOps movement.
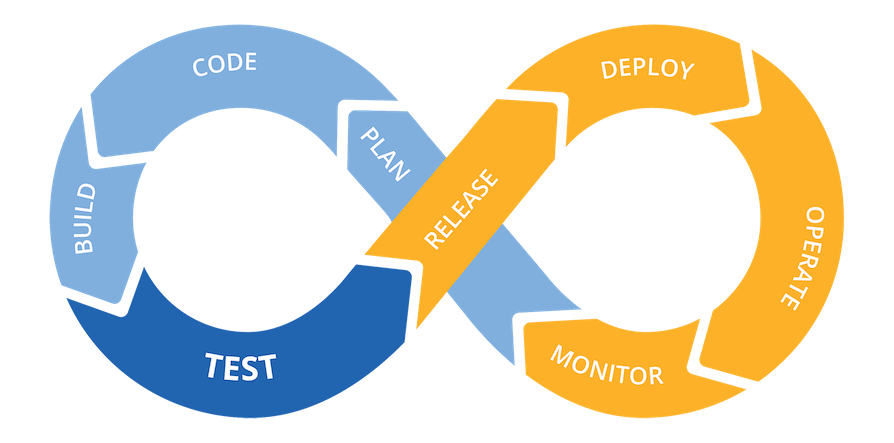
DevOps term first emerged somewhere around 2008 and 2009 and is attributed to Patrick Debois. In 2009 he held an event called DevOpsDays which main purpose was to bring together developers and system administrators and discuss the ways of how to bridge the gap between the two. This gained enough traction and the DevOps became a buzzword.
But what is DevOps? There is no academic definition, but the most common one states that it is a set of tools, practices, and philosophies aimed to bridge the gap between the development and operational teams in order to build quality software faster.
If you want to learn more about DevOps I recommend this 👉 awesome list.
DevOps has many aspects to it but I'd like to focus on three key practices which it brings: Infrastructure as Code, CI/CD, and version control.
Infrastructure as Code
According to Wikipedia, IaC is ...
... the process of managing and provisioning computer data centers through machine-readable definition files, rather than physical hardware configuration or interactive configuration tools.
What this really means is that you have a bunch of text files where you define the desired state of your infrastructure: number of VMs, their properties, virtual networks, IP addresses etc. etc. Then these files are processed by IaC tool or framework (Terraform, SaltStack, Ansible are just a few examples) which translates that declared state into actual API calls and configuration files and applies it to the infrastructure in order to bring it to the desired state. This gives you a level of abstraction since you focus only on the resulting state and not on how to achieve it. Here I should mention one of the key features of the IaC approach which is idempotence. This feature allows you to run an IaC tool repeatedly and if something is already in the desired state it won't touch it. For example, if you declare that a certain VLAN should be configured on a switch and it is already there when you run an IaC tool against that switch it won't try to configure anything.
Treating your infrastructure as text files enables you to apply the same tools and practices to infrastructure as one would apply to any other software project. CI/CD and version control are the main examples here.
CI/CD
CI/CD stands for Continuous Integration / Continuous Delivery or Deployment. Let's look into each component in more detail.
Continuous Integration — a process of frequent (up to several times a day) merges of code changes to the main code repository. These merges are accompanied by various tests and quality control processes such as unit and integration tests, static code analysis, extraction of documentation from the source code, etc. This approach allows to integrate code changes frequently by different developers therefore mitigating risks of integration conflicts.
Continuous Delivery — extension of CI which takes care of automating the release process (e.g. packaging, image building, etc). Continuous delivery allows you to deploy your application to the production environment at any time.
Continuous Deployment — extension of continuous delivery, but this time deployment to production is also automated.
Version control
A version control system is a foundation for any automation project. It tracks changes in your project files (source code), logs who made those changes, and enables CI/CD workflows.
Today Git is the de facto standard in version control systems. Essentially Git is just a command-line tool (though very powerful) that manages project versioning by creating and manipulating metadata kept in a separate hidden directory in the project's working directory. But all the magic comes with web-based source control systems such as GitHub or GitLab among others.
Many people confuse Git and GitHub because the latter became a generic term for version control systems.
Let's suppose you are on a team of developers working on a project hosted on GitHub. Your typical workflow will go like this:
- You want to make changes to the source code. It may be a bug fix or a new feature. You create a new branch from the main one and start making commits. This doesn't affect the main branch in any way.
-
When the work seems to be done it's time to create a pull request. PR is a way to tell other developers (project maintainers) that you want to merge your branch with the main one. PR creation can trigger CI tests if they are configured. After all CI tests pass successfully the code is reviewed by other team members. If CI tests fail or something needs to be improved the PR will be rejected. Then you can fix your code in the same branch and create another PR.
Usually, PR's are never merged automatically and someone needs to make the final decision.
-
If everything is good your branch will be merged with the main one.
- If CD is configured merging with the main branch triggers deployment to the production environment.
Summary
In this section, I gave a brief overview of what DevOps is and it's main tools and practices. In the next section, I'll try to explain how it can be applied to networks and network automation.